
Fine-tuning Code Completion Models with Refact.ai: Strategies for Improving Accuracy and Relevance


While code completion can significantly boost developer efficiency, there's a crucial factor to consider: accuracy and relevance. There are no doubts that it's made efficiency easier for developers who are trying to make development seamless; so many LLMs are available now that provide code completion and accuracy. However, these LLMs work with some models, and that is what they rely on to give information and do so many other things, like provide code suggestions and make them accurate. You may often notice the code suggestions provided by these LLMs may not be accurate and relevant enough to your code and this is where fine-tuning comes in. Usually, these LLMs are fixed to do something else; they're not fixed or tuned to understand your code by default because you haven't trained them on what you want them to do. To get the best out of any LLM, you have to train its model.
In this context, fine-tuning lets the LLM understand your code so it can enable accurate code generation for you. This technique is used because the model is not built to understand your code, so you have to train it to understand your code by using this technique. It just entails making adjustments and modifications to the models used in Refact.
In this article, you will learn about the basics of Refact, how it works, how its code completion model could be fine-tuned, and ways code accuracy and relevance could be improved. The article will delve deeper into the benefits of fine-tuning with Refact and explore strategies to improve code completion accuracy and relevance.
Prerequisites
An active RunPod account
Basic knowledge of fine-tuning.
Refact and Code Completion
Refact is basically a coding assistant that works with your IDEs (Visual Studio Code or JetBrains) and helps with code suggestions, refactoring, and also code support, with which you could use your natural language to communicate, and then it generates code based on the context provided. Refact's AI chat is dependent on two models: the GPT 3.5-Turbo and the GPT-4, which makes it very easy for Refact to understand the natural language or context provided and apply changes to your code or explain the code you want it to explain. Meanwhile, its a different case for code completion because there are two different ways code completion could be utilised. It could be self-hosted or used on the cloud using the Refact-1.6-fim model. When self-hosted, there are tons of models you could use, but it's advisable to work with the ones with fine-tuning support so you can make adjustments to understand your code better and work with it properly. For the self-hosted version, you need to have Docker installed on your local machine for great fine-tuning or a RunPod account to do the same.
There are a lot more things you can do with the basic features of Refact that were mentioned above. The AI chat feature can even help you fix bugs when explained in a natural language; it could even make your code understandable when asked to be made understandable. The code completion works just as an autocomplete for code. When you're writing some code in your IDE, for example, it provides suggestions based on how its tuned and the context of the code you're writing. The autocomplete feature works with over 20 programming languages, including Java, Python, TypeScript, and many others.
Fine-tuning with Refact
Fine-tuning is basically just a technique that could work in line with the code completion feature. It's a way of training the models to understand your code and work with it. Refact lets you pick its available models for fine-tuning, make adjustments to the self-hosted version, and even create models too. Before giving any practical steps, here are two things fine-tuning with Refact will do for you:
Better performance on code completion: By default, pre-trained models are good at general code stuff, but they could make things complex if they don't understand your code. They struggle so hard to understand your code because they don't know what you want in your codebase; they don't understand the pattern of your code, nor do they have any information about how the code structure should be. Fine-tuning comes in when you want to tune in the pre-trained model to do exactly what you want; it'll just be training the pre-trained model on what you want it to do and its code structure, making it better at suggesting accurate code. Fine-tuning lets the model learn the pattern of the code and style, which helps for better performance compared to using the suggestions given by a model that hasn't been fine-tuned. There are a couple of models with fine-tuning support in Refact's self-hosted version for code completion, such as
Refact/1.6B,starcoder/1b/base,codellama/7b, and a few others too.Efficiency: Fine-tuning relies on the knowledge of pre-trained models because training a model from scratch can be so stressful and time-consuming. It lets you focus on training the pre-trained model for a specific task. In this context, you can pick any of Refact's self-hosted models for code completion that supports fine-tuning, and train any of them to work on the specific task you want them to work on. It reduces time; you can achieve better results by fine-tuning rather than training an entire model from scratch.
How to fine-tune a Refact Model
Fine-tuning a Refact model is training a pre-trained model to provide better code suggestions that are tailored for your project. There are a couple of steps you need to complete to fine-tune your Refact model or any model that works with Refact. In this article, we will be using the self-hosted version of Refact to have more control over the data used for fine-tuning; using the cloud version will give limited control for fine-tuning.
Getting access to the self-hosted instance and uploading datasets: The datasets are what the model will be trained on. You may be wondering what data to use before anything. The model will only learn to suggest accurate code based on what is provided in the datasets. The datasets are what the model will rely on for improved code completion accuracy, as they are the most crucial element for fine-tuning. In this context, the dataset could be a GitHub repository that has a relationship to what you're building because it leverages your codebase for proper fine-tuning. For example, if you're working on a weather app, you provide code sources such as the API or even the tech stack you're building on.
If you have the Docker CLI installed, run this command to get access to Refact's self-hosted instance:
docker run -d --rm -p 8008:8008 -v perm-storage:/perm_storage --gpus all smallcloud/refact_self_hostingBut in this article, we will be using RunPod - just if you do not have an account, create one. After doing so, choose the Refact template in RunPod and let it work with any of the GPU cloud models you'll want it to work with.
After doing that, you should see this; click the continue button and deploy. Copy the value it gives on the pop-up and run it on your SSH terminal.
After that, you should get a URL that navigates to the Web GUI for Refact. Click on the Sources tab on the header and should see this:
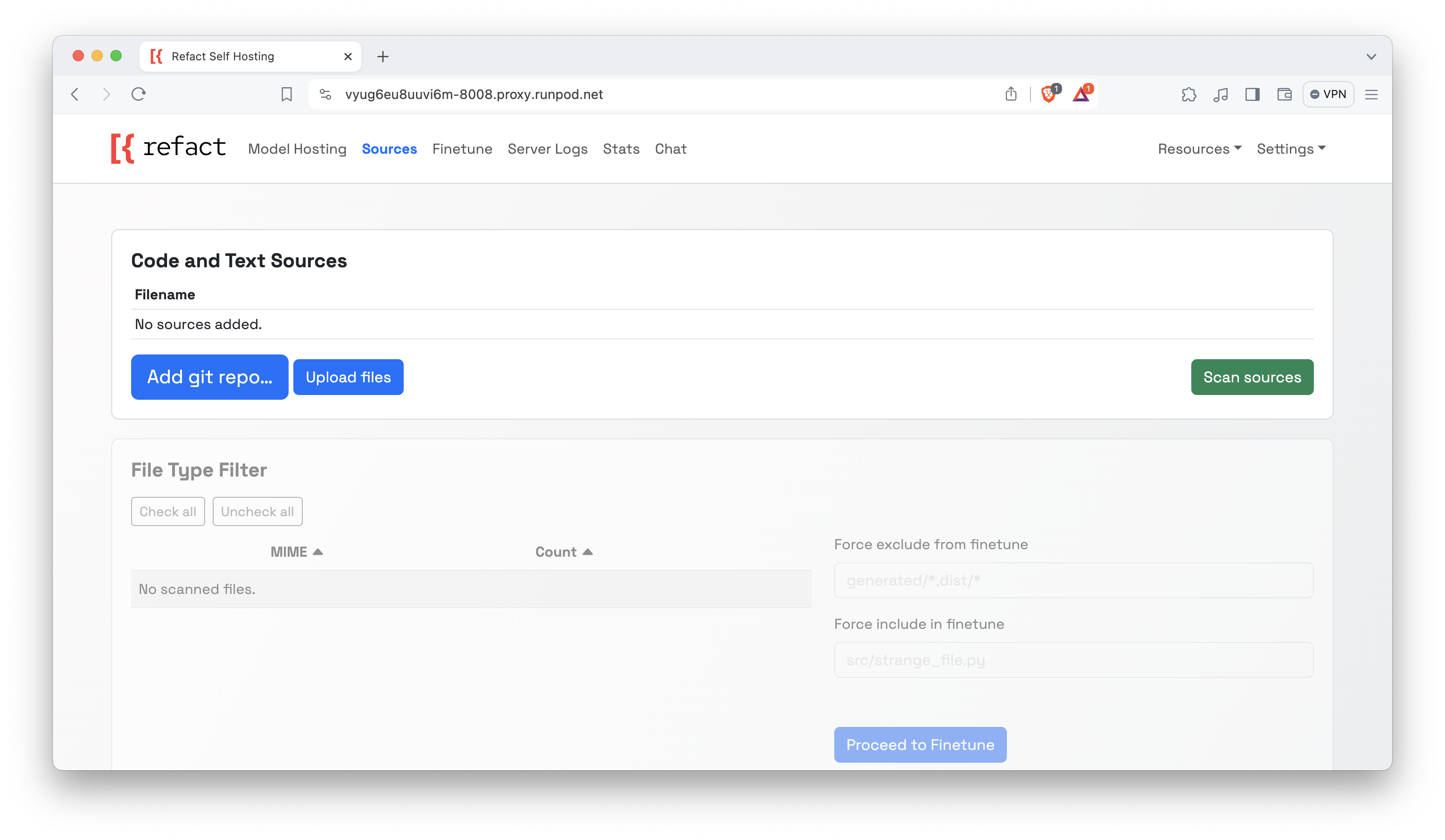
Apparently, this is where the real work begins. You need to add the code sources—what you'll want the model to be trained on—in this context. You have the option of choosing either the files of your code or the GitHub repository. In my case, I will be uploading the entire code of a project I built, GitHub Star History, because I want it to understand the style of the code and all sorts of that.

Once done, it's time to scan your code source(s)!
Scanning datasets in Refact: As you know, datasets in this context are your code sources. Scanning your code sources is just analyzing your code and filtering out unnecessary code for proper fine-tuning. In this process, you'll be able to see the files that will be accepted for fine-tuning and the rejected ones. To ensure you have a seamless experience with fine-tuning, you need to scan the files provided. Now you may be wondering what files were rejected and why they were rejected. It could be because there is probably no text in that file, file size is too large, it is probably a duplicated file, could be a linguist error, etc.

Once you see this, you're free to check the accepted and rejected ones. Be sure to click on the MIME's that you want to fine-tune. Then, you can click on the "Proceed to Finetune" button.
Fine-tuning the Refact LLM: This is the most crucial part, and it involves two things: filtering and training. Filtering is almost the same process as scanning, but it's just about making sure you have good code provided before training. In this filtering stage, you may also see accepted and rejected files.
For training, it takes a lot of time, and Refact provides so much transparency that it lets you monitor the training progress. Before anything, ensure you pick the model you want, even before filtering.
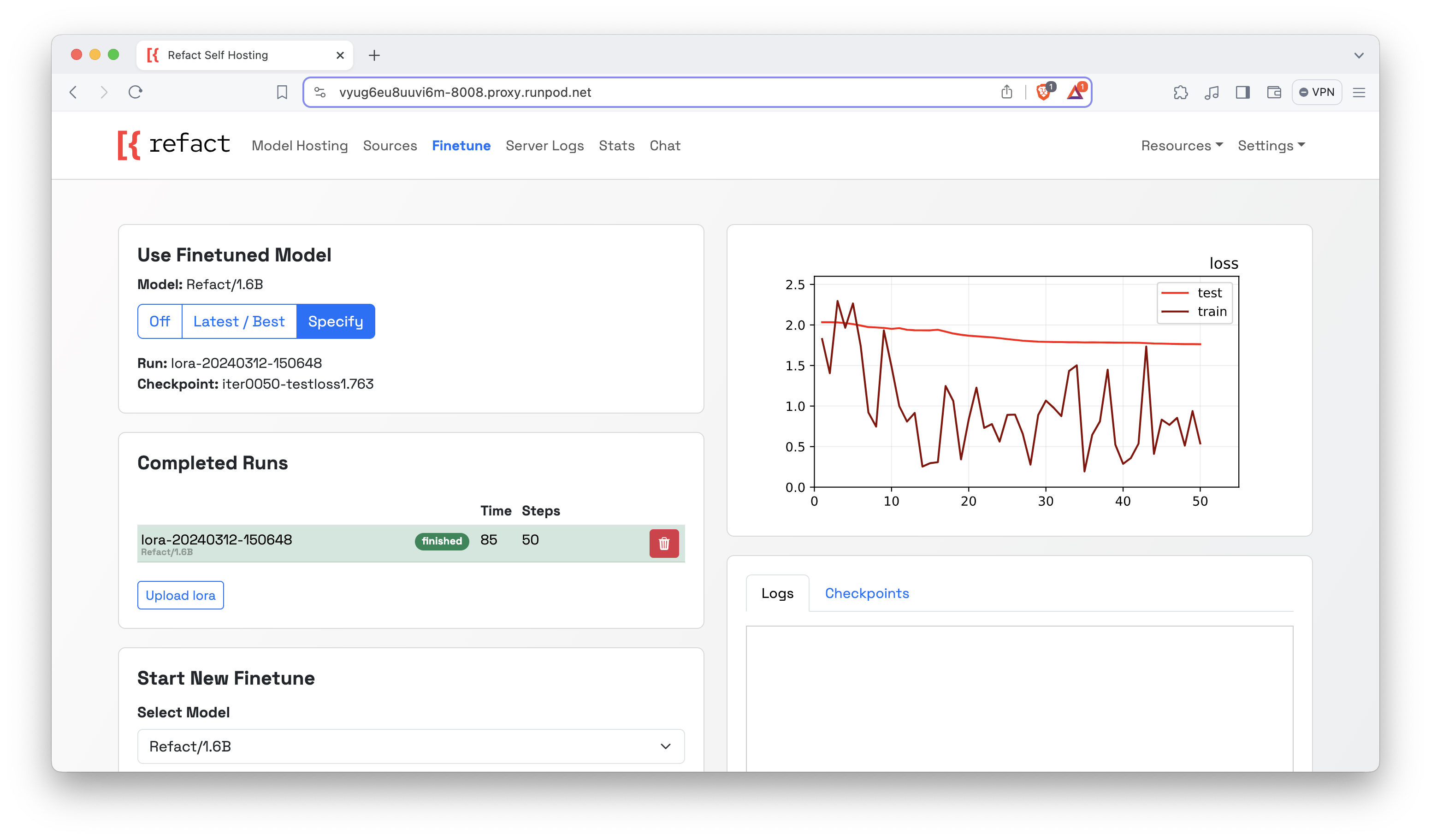
You can then look at the logs. This way, you've fine-tuned the LLM; it's trained to give code suggestions that relate to what you're working on.
Utilizing the fine-tuned LLM
After completing the steps provided in this article, it'll be fun to see how your LLM is trained. In your IDE (either VSCode or JetBrains), choose the self-hosted option and provide the endpoint. This way, it should work (using VSCode). Now, you want to see how the LLM has been trained for code completion. You could see it just just like this:

Just as I provided the code for what I've been working on, GitHub Star History. The model was trained to work with the project for code completion. So this way, if there is anything I'm trying to add to this code, it automatically suggests a good code to add. This is an example of what happens when your code is trained properly!
Strategies for improving accuracy with Refact
To make code completion more accurate in Refact, there are a couple of things that could be done. In code completion, you can't be assured of 100% accuracy, but your accuracy level can only be improved. Here are just a few strategies for improving code completion accuracy in Refact:
Provide good code: When you provide good code, your code is definitely going to be given good suggestions for code completion. The model should be tuned properly with good code, as it also helps the model understand what you are trying to achieve. If the model is trained with code filled with so many errors, or code that isn't properly written, then it won't give the suggestions you're looking for. So, it's important that you provide transparency in your code by making it clean and great to use for the LLM.
Use different styles in your code: In your project, ensure you have different patterns of code; if you use just one style, it increases bias, and this may result in giving code suggestions that may not work accurately. Using different styles could train the model to give more accurate code and get rid of difficulties.
Continuous Performance Tracking: Monitor your Refact model regularly by testing; be sure to perform checks on its relevance and accuracy. It helps you identify areas of improvement (making the code more structured or providing a better one), and the effectiveness of your fine-tuning.
Strategies for improving relevance with Refact
There are also a couple of steps if you want to make sure your fine-tuned model is more relevant.
Review Code Sources: Be sure to filter before training - it helps in highlighting code with issues or suggesting improvements. This method not only provides a review of the correct code structure but also helps it understand the desired coding style and best practices within your domain.
Provide clear and concise code: Before anything, frame your code with clarity and detail. Include relevant context about the project, the functionalities of the code, and the desired outcome. The more specific your code is, the better Refact can tailor its suggestions to your needs.
Providing a Better Context: Ensure you don't leave your Refact model in the dark! Have relevant code from surrounding functions or variables. This context helps the Refact model understand how the new code snippet should fit in.
Conclusion
By following these practices, you can transform Refact from a basic code completion tool into a highly relevant and context-aware partner, accelerating your development workflow and ensuring your code adheres to your project's specific coding conventions. Remember, fine-tuning is an ongoing process. As your project evolves, continue to refine your training data, prompts, and feedback to ensure Refact remains a valuable asset in your development environment.
I hope that in this article, you've gone a lot beyond what the topic says. Many thanks for getting to the end of this article, I hope this was a great read. See ya!